






 当前位置:
当前位置: 来源:互联网转载
来源:互联网转载  作者:版权所有者
作者:版权所有者  时间:2023-09-07 10:17:35 发布
时间:2023-09-07 10:17:35 发布  标签:新闻
标签:新闻只需几张图像,用文本即可生成任意年龄图像,用户反馈准确率达80%!
当下的「人脸识别系统」抗衰老能力非常弱,人物面部老化会显著降低识别性能,隔一段时间就需要更换人脸数据。

提升人脸识别系统的鲁棒性需要收集个体老化的高质量数据,不过近几年发布的数据集规模通常较小,年限也不够长(如5年左右),或是在姿态、照明、背景等方面有较大变化,没有专注于人脸数据。
最近,纽约大学的研究人员提出了一种通过隐扩散模型保留不同年龄身份特征的方法,并且只需要少样本训练,即可直观地用「文本提示」来控制模型输出。

论文链接:https://arxiv.org/pdf/2307.08585.pdf
研究人员引入了两个关键的组件:一个身份保持损失,以及一个小的(图像,描述)正则化集合来解决现有的基于GAN的方法所带来的限制。
在两个基准数据集CeleA和AgeDB的评估中,在常用的生物特征忠诚度(biometric fidelity)指标上,该方法比最先进的基线模型在错误不匹配率上降低了约44%
追踪人脸的年龄变化
追踪人脸的年龄变化
DreamBooth
文中提出的方法基于潜扩散模型DreamBooth,其可以通过对文生图扩散模型微调的方式将单个主体放置在其他上下文(re-contextualization)中。
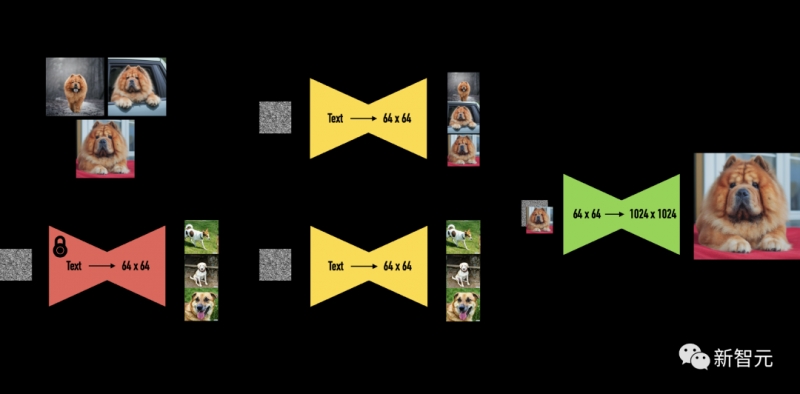
Dreambooth的输入要求为目标主体多张图像,以及包含主体的唯一标识符和类标签(class label)的文本提示,其中类标签是多个实例的集合表示,主体对应于属于该类的特定示例。
Dreambooth的目标是将唯一标识符与每个主体(类的特定实例)相关联,然后在文本提示的指导下,在不同的上下文中重新创建同一主体的图像。
类标签需要利用指定类别预训练扩散框架的先验知识,如果类别标签不正确或丢失可能会导致输出质量下降,唯一token充当对特定主题的引用,并且需要足够少见以避免与其他常用概念冲突。
原文作者使用了一组少于3个Unicode字符序列作为token,并用T5-XXL作为分词器。
DreamBooth使用类别先验保存损失(class-specific prior preservation loss)来增加生成图像的可变性,同时确保目标对象和输出图像之间的偏差最小,原始训练损失如下:
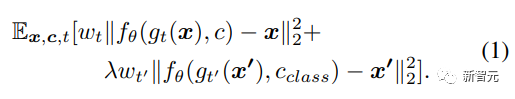
DreamBooth在先验保存的帮助下可以有效地合成狗、猫、卡通等主体图像,不过这篇论文中主要关注的是结构更复杂、纹理也偏细节的人脸图像。
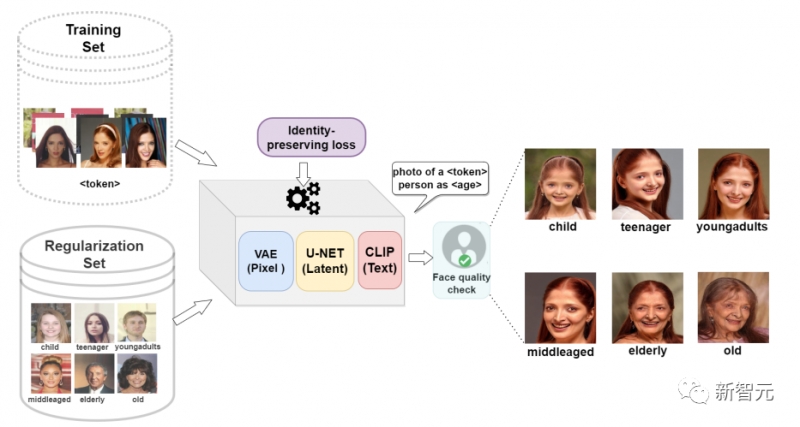
虽然类标签「person」可以捕获类似人类的特征,但这可能不足以捕获因个体差异而形成的身份特征。
所以研究人员在损失函数中引入了一个身份保存(identity-preserving)项,可以最小化原始图像和生成图像生物特征之间的距离,并用新的损失函数微调VAE。
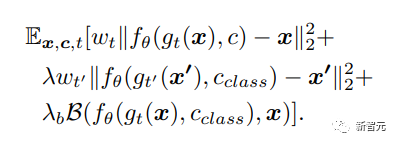
公式中的第三项代表被拍摄物体的真实图像和生成图像之间生物特征距离,其中B代表两张图像的L1距离,相同的图像距离接近0,值越大代表两个主体的差异越大,使用预训练VGGFace作为特征抽取器。
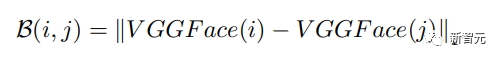
下一步是针对特定目标进行微调,使用冻结的VAE和文本编码器,同时保持U-Net模型解冻。
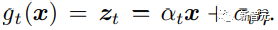
UNet对VAE的编码器产生的潜在表征进行去噪,使用身份保持对比损失进行训练。
研究人员采用SimCLR框架,使用正负样本对之间的归一化温标交叉熵损失(temperature-scaled cross-entropy loss)来增强潜在表征,即下式中的S函数。
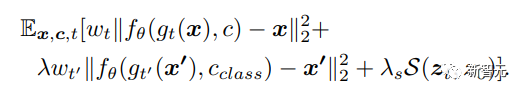
在加权项λs=0.1且温度值=0.5的情况下,计算无噪声输入(z0)和去噪声输出(zt)的潜在表征之间的对比损失。
U-Net架构中潜在表征之间的对比损失使得模型能够微调不同主体的扩散模型。
除了定制损失外,研究人员还使用正则化集将面部年龄发展(progression)和回归(regression)的概念赋给潜在扩散模型,其中正则化集合包括一个类别中所有代表性的图像,在本例中为person.
如果目标是生成真实的人脸图像,那从互联网上选择人脸图像的正则化集就足够了。
不过本文中的任务是让模型学习衰老和返老还童的概念,并且还要应用到不同的个体上,所以研究人员选择使用不同年龄组的人脸图像,然后将其与一个单词描述(one-word caption)进行配对。
图像描述对应于六个年龄组 :儿童(child)、青少年(tennager)、年轻人(youngadults)、中年人(middleaged)、中老年人(elderly)、老年人(old )。
相比数字提示(20岁、40岁),年龄描述的性能更好,并且可以在推理中用文本来提示扩散模型((photo of a ⟨ token ⟩ ⟨ class label ⟩ as ⟨ age group ⟩)
实验结果
实验设置
研究人员使用Stable Diffusion v1.4实现的DreamBooth进行实验,使用CLIP文本编码器(在laion-aesthetics v2 5+上训练)和矢量量化VAE来完成年龄变化,在训练扩散模型时,文本编码器保持冻结状态。
研究人员使用来自CelebA数据集100名受试者的2258张人脸图像和来自AgeDB数据集100名受试者的659张图像构成训练集。

除了二元属性「Young」之外,CelebA数据集没有受试者的年龄信息;AgeDB数据集包含精确年龄值,研究人员选择图像数量最多的年龄组,并将其用作训练集,其余图像则用于测试集(共2369幅图像)。
研究人员使用(图像,描述)数据对作为正则化集,其中每个人脸图像与指示其相应年龄标签的标题相关联,具体儿童<15岁、青少年15-30岁、年轻人30-40岁、中年人40-50岁、中老年人50-65岁、老年人>65岁,使用四个稀少token作为标记:wzx, sks, ams, ukj
对比结果
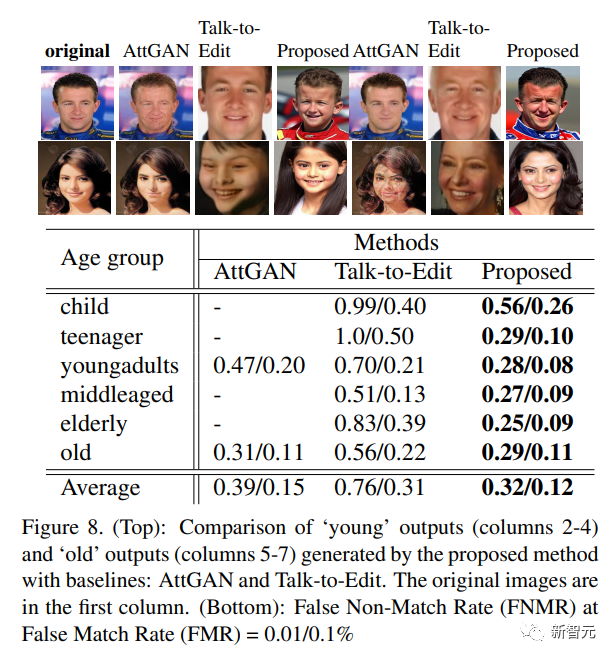
研究人员使用IPCGAN、AttGAN和Talk-toEdit作为评估对比基线模型。
由于IPCGAN是在CACD数据集上训练的,所以研究人员对来自CACD数据集的62名受试者进行了微调,可以观察到FNMR=2%,而文中提出的方法FNMR( False NonMatch Rate)=11%

可以看到IPCGAN默认情况无法执行老化或变年轻的操作,导致FNMR值很低。
研究人员使用DeepFace年龄预测器进行自动年龄预测,可以观察到,与原始图像和IPCGAN生成的图像相比,文中方法合成的图像会让年龄预测得更分散,表明年龄编辑操作已经成功。
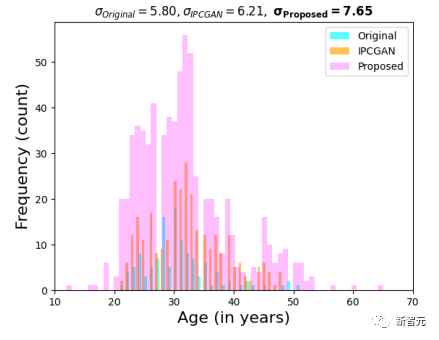
在CelebA数据集上应用AttGAN和对话编辑时,在图像对比和生物特征匹配性能上,可以观察到,在FMR=0.01时,文中方法在「young」类别的图像上优于AttGAN 19%,在「old」类别图像上优于AttGAN 7%
用户研究
研究人员收集了26份用户反馈,rank-1生物特征识别准确率(响应总数的平均值)达到了78.8%,各年龄组的正确识别准确率分别为:儿童=99.6%、青少年=72.7%、青少年=68.1%、中年=70.7%、老年人=93.8%

也就是说,用户能够以相当高的准确度成功地区分来自不同年龄组的生成图像。






























