摘要
ChatGPT刚发布的时候,给了我们太多的震撼,模型在对话上的表现实在是太像人类了,以至于产生了语言模型具有「思维能力」的错觉。...
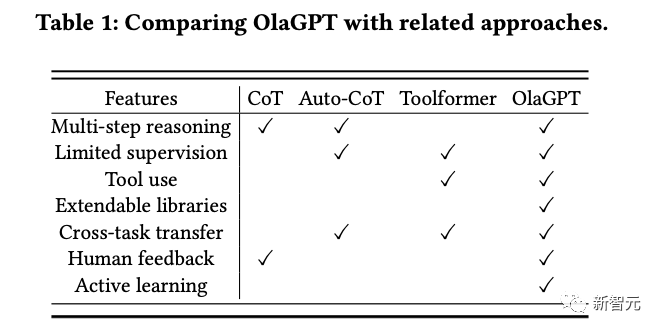
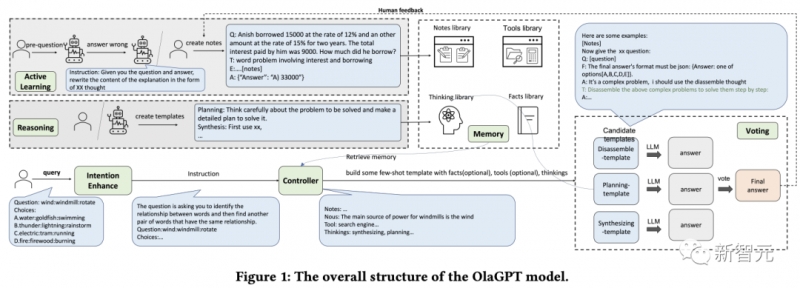
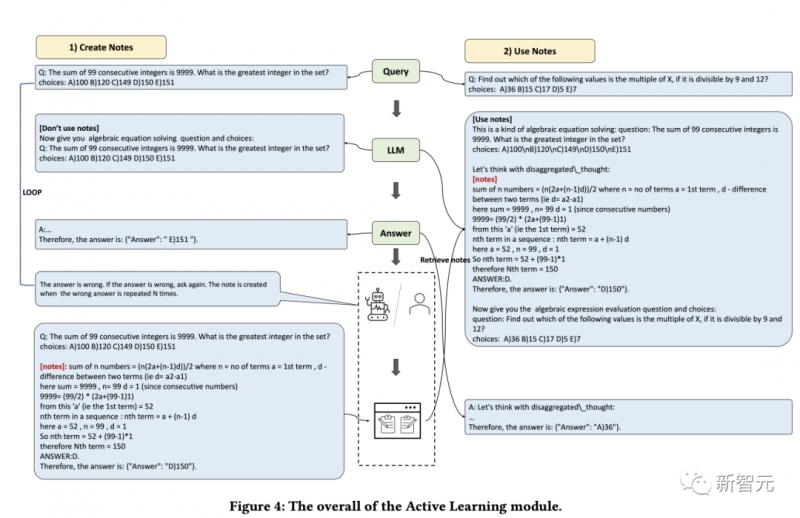
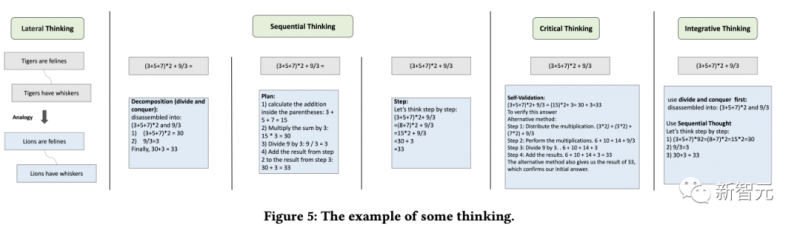
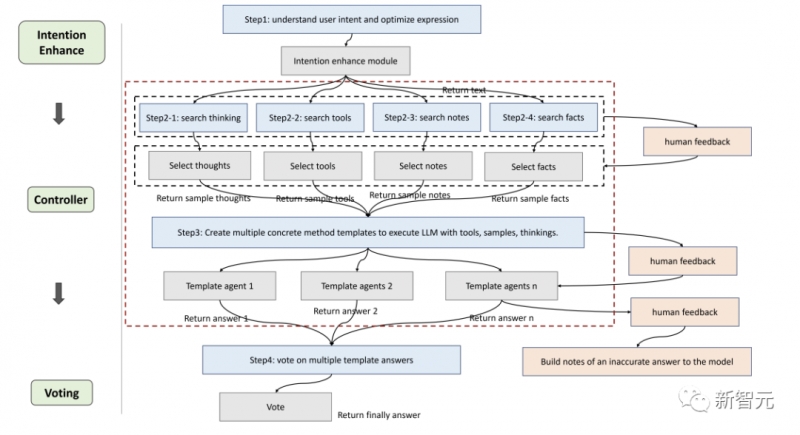
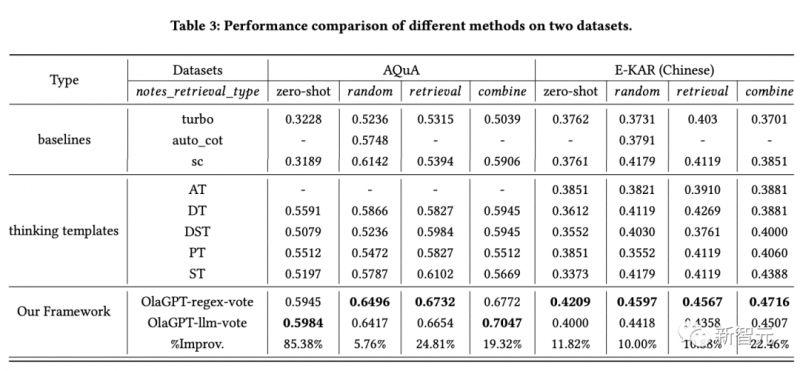
ChatGPT刚发布的时候,给了我们太多的震撼,模型在对话上的表现实在是太像人类了,以至于产生了语言模型具有「思维能力」的错觉。不过在深入了解语言模型之后,研究人员们也逐渐发现了,基于高概率语言模式的再现与期望中的「通用人工智能」还有很大差距。在当前的大多数研究中,大型语言模型主要是在特定提示的引导下生成思维链来执行推理任务,没有考虑人类的认知框架,使得语言模型解决复杂推理问题的能力与人类之间仍然存在着显着的差距。人类在面对复杂的推理难题时,通常会使用各种认知能力,并且需要与工具、知识和外部环境信息的各个方面进行交互,那语言模型能不能模拟人类的思维流程来解决复杂问题呢?答案当然是可以!首个模拟人类认知处理框架的模型OlaGPT来了!论文链接:https://arxiv.org/abs/2305.16334代码链接:https://github.com/oladata-team/OlaGPTOlaGPT包括多个认知模块,包括注意力、记忆、推理、学习,以及相应的调度和决策机制;受人类主动学习启发,框架中还包括一个学习单元来记录之前的错误和专家意见,并动态参考来提升解决类似问题的能力。文中还概述了人类解决问题的常见有效推理框架,并相应地设计了思维链(CoT)模板;还提出了一个全面的决策机制,可以最大限度地提高模型的准确性。在多个推理数据集上进行了严格评估后得到的实验结果表明,OlaGPT超越了此前最先进的基准,证明了其有效性。目前的语言模型与期望中的通用人工智能还有很大差距,主要表现为:1. 在某些情况下生成的内容毫无意义,或者偏离了人类的价值偏好,甚至会给出一些非常危险的建议,目前的解决方案是引入人类反馈的强化学习(RLHF)对模型输出进行排序。2. 语言模型的知识仅限于在训练数据中明确提到的概念和事实。在面对复杂问题时,语言模型也无法像人类一样适应变化的环境、利用现有的知识或工具、反思历史教训、分解问题,以及使用人类在长期进化中总结出的思维模式(如类比、归纳推理和演绎推理等)来解决问题。不过,让语言模型模拟人脑处理问题的过程还有许多系统难题:1. 如何系统地模仿和编码人类认知框架中的主要模块,同时以可实现的方式根据人类的通用推理模式进行调度?2. 如何引导语言模型像人类一样进行主动学习,即从历史错误或专家对困难问题的解决方案中学习和发展?虽然重新训练模型对纠正后的答案进行编码可能是可行的,但显然成本很高而且不灵活。3. 如何让语言模型灵活地利用人类进化出的各种思维模式,从而提高其推理性能?一个固定的、通用的思维模式很难适应不同问题,就像人类在面对不同类型的问题时,通常会灵活地选择不同的思维方式,如类比推理、演绎推理等。OlaGPT是一个模拟人类思维的问题解决框架,可以增强大型语言模型的能力。OlaGPT借鉴了认知架构(cognitive architecture)理论,把认知框架的核心能力建模为注意力(attention)、记忆(memory)、学习(learning)、推理(reasoning)、行动选择(action selction)。研究人员根据具体实现的需要对该框架进行了微调,并提出了一个适合语言模型解决复杂问题的流程,具体包括六个模块:意图增强模块(注意力)、记忆模块(记忆)、主动学习模块(学习)、推理模块(推理)、控制器模块(行动选择)和投票模块。注意力是人类认知的一个重要组成部分,识别出相关的信息并过滤掉不相关的数据。同样地,研究人员为语言模型设计了相应的注意力模块,即意图增强,旨在提取最相关的信息,并在用户输入和模型的语言模式之间建立更强的关联,可以被看作是一个从用户表达习惯到模型表达习惯的优化转换器。首先通过特定的提示词提前获得LLMs的问题类型,然后重构提问的方式。比如在问题的开头加上一句「Now give you the XX(问题类型),question and choices:」;为了便于分析,提示中还需要加入「The answer must end with JSON format: Answer: one of options[A,B,C,D,E].」记忆模块在存储各种知识库信息方面起着至关重要的作用,已经有研究证明了当下语言模型在理解最新事实数据方面的局限性,而记忆模块着重于巩固模型尚未内化的知识,并将其作为长期记忆储存在外部库中。研究人员使用langchain提供的记忆功能进行短期记忆,长期记忆则由基于Faiss的矢量数据库实现。在查询过程中,其检索功能可以从库中提取相关知识,涵盖了四种类型的记忆库:事实、工具、笔记和思维(thinking),其中事实是现实世界的信息,如常识等;工具包括搜索引擎、计算器和维基百科,可以协助语言模型完成一些无需为条的工作;笔记主要记录一些疑难案例和解决问题的步骤;思考库主要存储由专家编写的人类解决问题的思考模板,专家可以是人类,也可以是模型。学习的能力对于人类不断提升自我表现来说至关重要,从本质上讲,所有形式的学习都依赖于经验,语言模型可以从之前的错误中学习,从而实现快速提高推理能力。首先,研究人员找出语言模型无法解决的问题;然后在笔记库中记录专家提供的见解和解释;最后选择相关的笔记来促进语言模型的学习,从而可以更有效地处理类似问题。推理模块的目的是创建基于人类推理过程的多个智能体,从而激发语言模型的潜在思维能力,进而解决推理问题。该模块结合了多种思维模板,参考特定的思维类型,如横向思维、顺序思维、批判性思维和整合性思维,以促进推理任务。控制器模块主要用来处理相关的行动选择,具体包括模型的内部规划任务(如选择某些模块来执行)以及从事实、工具、笔记和思维库中选择。首先检索和匹配相关的库,检索到的内容随后被整合到一个模板智能体中,要求语言模型以异步的方式在一个模板下提供回复,就像人类在推理之初可能难以识别所有的相关信息一样,同样很难期望语言模型一开始就做到这一点。因此,动态检索是根据用户的问题和中间的推理进度来实现的,使用Faiss方法为上述四个库创建嵌入索引,其中各个库的检索策略略有不同。由于不同的思维模板可能更适合不同类型的问题,研究人员设计了投票模块来提升多个思维模板之间的集成校准能力,并多种投票策略来生成最佳答案以提高性能。1. 语言模型投票:引导语言模型在多个给定的选项中选择最一致的答案,并提供一个理由。2. regex投票:用正则表达式精确匹配抽取答案以获取投票结果。为了评估该增强型语言模型框架在推理任务中的有效性,研究人员在两类推理数据集上进行了全面的实验比较。1. SC(self-consistency)的性能优于GPT-3.5-turbo,表明在一定程度上采用集成方法确实有助于提高大规模模型的有效性。2. 文中提出方法的性能超过了SC,在一定程度上证明了思维模板策略的有效性。不同思维模板的答案表现出相当大的差异,在不同的思维模板下进行投票,最终会比简单地进行多轮投票产生更好的结果。3. 不同思维模板的效果是不同的,循序渐进的解决方案可能更适合推理型问题。具体来说,随机、检索和组合列表现出更高的性能,即将具有挑战性的案例作为笔记库纳入其中是一种可行的策略。5. 不同的检索方案在不同的数据集上有不同的效果,总的来说,组合(combine)策略的效果更好。6. 文中方法明显优于其他方案,这得益于整体框架的合理设计,包括主动学习模块的有效设计;思维模板实现了对不同模型的适应,不同思维模板下的结果是不同的;控制器模块起到了很好的控制作用,选择了与所需内容比较匹配的内容;投票模块设计的不同思维模板的集成方式是有效的。
https://github.com/oladata-team/OlaGPT

原标题:首个模拟人类认知的思维框架OlaGPT:推理能力最高提升85%
特别声明:本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,并不意味着赞同其观点或者证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来函camelboy#163.com联系,会在24小时内删除。
Notice: The articles / pictures and other manuscripts that this website notes as the source of manuscripts from other media are reprinted manuscripts, which does not mean that they agree with their views or confirm the authenticity of their contents. If the reprinted manuscript involves copyright and other issues, please contact the author by letter within two weeks.







 当前位置:
当前位置: 来源:互联网转载
来源:互联网转载  作者:版权所有者
作者:版权所有者  时间:2023-06-05 09:48:27 发布
时间:2023-06-05 09:48:27 发布  标签:新闻
标签:新闻

















 京公网安备11010502032209号 | 京ICP备20032164号 | XML地图
京公网安备11010502032209号 | 京ICP备20032164号 | XML地图


















