当前位置:
当前位置: 来源:互联网转载
来源:互联网转载  作者:版权所有者
作者:版权所有者  时间:2023-05-15 01:46:35 发布
时间:2023-05-15 01:46:35 发布  标签:新闻
标签:新闻ChatGPT在内的OpenAI大模型,也支持OpenAssistant等免费大模型。Transformer Agent负责“教会”这些大模型直接调用Hugging Face上的任意AI模型,并输出处理好的结果。...
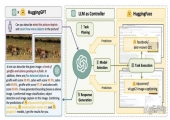
只需和ChatGPT聊聊天,它就能帮你调用10万+个HuggingFace模型!
这是抱抱脸最新上线的功能HuggingFace Transformers Agents,一经推出就获得极大关注:
这个功能,相当于给ChatGPT等大模型配备了“多模态”能力——
不限于文本,而是图像、语音、文档等任何多模态任务都能解决。
例如告诉ChatGPT“解释这张图像”,并扔给它一张海狸照片。ChatGPT就能调用图像解释器,输出“海狸正在水里游泳”:

随后,ChatGPT再调用文字转语音,分分钟就能把这句话读出来。
当然,它不仅支持ChatGPT在内的OpenAI大模型,也支持OpenAssistant等免费大模型。
Transformer Agent负责“教会”这些大模型直接调用Hugging Face上的任意AI模型,并输出处理好的结果。
所以这个新上线的功能,背后的原理究竟是什么?
如何让大模型“指挥”各种AI?
简单来说,Transformers Agents是一个大模型专属的“抱抱脸AI工具集成包”。
HuggingFace上各种大大小小的AI模型,都被收纳在这个包里,并被分门别类为“图像生成器”、“图像解释器”、“文本转语音工具”……
同时,每个工具都会有对应的文字解释,方便大模型理解自己该调用什么模型。
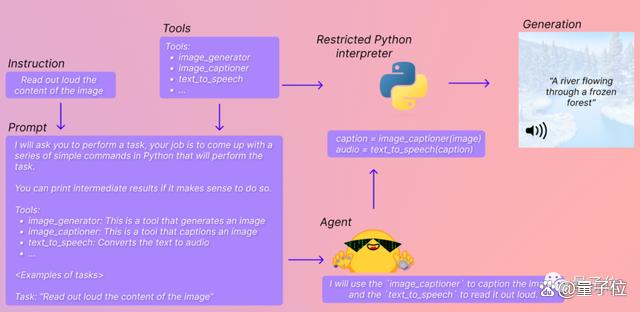
这样一来,只需要一段简单的代码+提示词,就能让大模型帮助你直接运行AI模型,并将输出结果实时返还给你,过程一共分为三步:
首先,设置自己想用的大模型,这里可以用OpenAI的大模型(当然,API要收费):
from transformers import OpenAiAgentagent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")也可以用BigCode或OpenAssistant等免费大模型:
from huggingface_hub import loginlogin("<YOUR_TOKEN>")然后,设置Hugging Transformers Agents。这里我们以默认的Agent为例:
from transformers import HfAgent# Starcoderagent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")# StarcoderBase# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")# OpenAssistant# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
接下来,就可以使用run()或者chat()两个指令,来运行Transformers Agents了。
run()适合同时调用多个AI模型,执行比较复杂专业的任务。
可以调用单个AI工具。
例如执行agent.run(“Draw me a picture of rivers and lakes.”),它就能调用AI文生图工具帮你生成一张图像:

也可以同时调用多个AI工具。
例如执行agent.run(“Draw me a picture of the sea then transform the picture to add an island”),它就能调用“文生图”和“图生图”工具,帮你生成对应图像:

chat()则适合以聊天的方式“持续完成任务”。
例如,先调用文生图AI工具,生成一个河流湖泊图片:agent.chat(“Generate a picture of rivers and lakes”)

再在这张图片的基础上做“图生图”修改:agent.chat(“Transform the picture so that there is a rock in there”)

要调用的AI模型可以自行设置,也可以使用抱抱脸自带的一套默认设置来完成。
已设置一套默认AI模型
目前,Transformers Agents已经集成了一套默认AI模型,通过调用以下Transformer库中的AI模型来完成:
1、视觉文档理解模型Donut。给定图片格式的文件(PDF转图片也可以),它就能回答关于这个文件的问题。
例如问“TRRF科学咨询委员会会议将在哪里举行”,Donut就会给出答案:

2、文字问答模型Flan-T5。给定长文章和一个问题,它就能回答各种文字问题,帮你做阅读理解。
3、零样本视觉语言模型BLIP。它可以直接理解图像中的内容,并对图像进行文字说明。
4、多模态模型ViLT。它可以理解并回答给定图像中的问题,
5、多模态图像分割模型CLIPseg。只需要给它一个模型和一个提示词,它就能根据这个提示分割出图像中指定的内容(mask)。
6、自动语音识别模型Whisper。它可以自动识别一段录音中的文字,并完成转录。
7、语音合成模型SpeechT5。用于文本转语音。
8、自编码语言模型BART。除了可以自动给一段文字内容分类,还能做文本摘要。
9、200种语言翻译模型NLLB。除了常见语言外,还能翻译一些不太常见的语言,包括老挝语和卡姆巴语等。
通过调用上面这些AI模型,包括图像问答、文档理解、图像分割、录音转文字、翻译、起标题、文本转语音、文本分类在内的任务都可以完成。
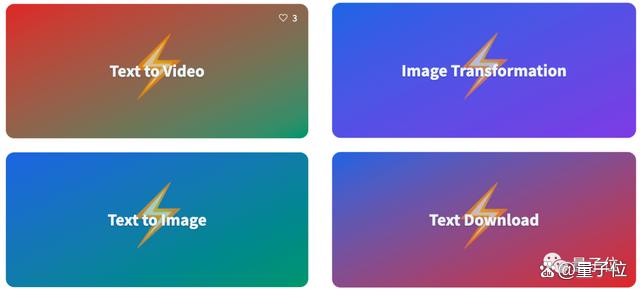
除此之外,抱抱脸还“夹带私货”,包含了一些Transformer库以外的模型,包括从网页下载文本、文生图、图生图、文生视频:
这些模型不仅能单独调用,还可以混合在一起使用,例如要求大模型“生成并描述一张好看的海狸照片”,它就会分别调用“文生图”和“图片理解”AI模型。
当然,如果我们不想用这些默认AI模型,想设置一套更好用的“工具集成包”,也可以根据步骤自行设置。
对于Transformers Agents,也有网友指出,有点像是LangChainagents的“平替”:
你试过这两个工具了吗?感觉哪个更好用?