




 当前位置:
当前位置: 来源:教育信息网
来源:教育信息网  作者:版权所有者
作者:版权所有者  时间:2023-04-03 02:48:01 发布
时间:2023-04-03 02:48:01 发布 目前,HuggingGPT的论文已经发布,项目则正在建设中,代码只开源了一部分,已揽获1.4k标星。我们注意到,它的项目名称很有意思,不叫本名HuggingGPT,而是钢铁侠里的AI管家贾维斯(JARVIS)。...
最强组合:HuggingFace+ChatGPT —— HuggingGPT,它来了!
只要给定一个AI任务,例如“下面这张图片里有什么动物,每种有几只”。
它就能帮你自动分析需要哪些AI模型,然后直接去调用HuggingFace上的相应模型,来帮你执行并完成。
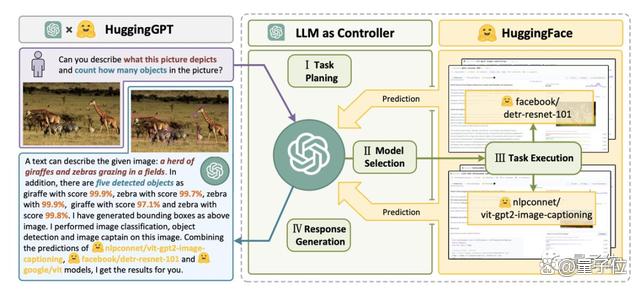
整个过程,你要做的就只是用自然语言将你的需求输出。
这项由浙大与微软亚研院的合作成果,一经发布就迅速爆火。
英伟达AI研究科学家Jim Fan直呼:
这是我本周读到的最有意思的论文。它的思想非常接近“Everything App”(万物皆App,被AI直接读取信息)。
而一位网友则“直拍大腿”:
这不就是ChatGPT“调包侠”吗?
AI进化速度一日千里,给我们留口饭吃吧……

所以,具体怎么回事儿?
HuggingGPT:你的AI模型“调包侠”
其实,若说这个组合物只是“调包侠”,那格局小了。
它的真正用义,是AGI。
如作者所言,迈向AGI的关键一步是能够解决具有不同领域和模式的复杂AI任务。
我们目前的成果离此还有距离——大量模型只能出色地完成某一特定任务。
然而大语言模型LLM在语言理解、生成、交互和推理方面的表现,让作者想到:
可以将它们作为中间控制器,来管理现有的所有AI模型,通过“调动和组合每个人的力量”,来解决复杂的AI任务。
在这个系统中,语言是通用的接口。
于是,HuggingGPT就诞生了。
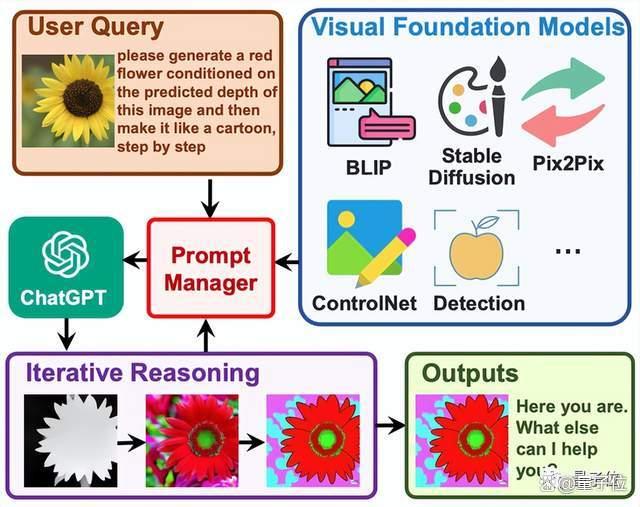
它的工程流程分为四步:
首先,任务规划。ChatGPT将用户的需求解析为任务列表,并确定任务之间的执行顺序和资源依赖关系。
其次,模型选择。ChatGPT根据HuggingFace上托管的各专家模型的描述,为任务分配合适的模型。
接着,任务执行。混合端点(包括本地推理和HuggingFace推理)上被选定的专家模型根据任务顺序和依赖关系执行分配的任务,并将执行信息和结果给到ChatGPT。
最后,输出结果。由ChatGPT总结各模型的执行过程日志和推理结果,给出最终的输出。
如下图所示。
假定我们给出这样一个请求:
请生成一个女孩正在看书的图片,她的姿势与example.jpg中的男孩相同。然后请用你的声音描述新图片。
可以看到HuggingGPT是如何将它拆解为6个子任务,并分别选定模型执行得到最终结果的。

具体效果怎么样?
作者采用gpt-3.5-turbo和text-davinci-003这俩可以通过OpenAI API公开访问的变体,进行了实测。
如下图所示:
在任务之间存在资源依赖关系的情况下,HuggingGPT可以根据用户的抽象请求正确解析出具体任务,完成图片转换。

在音频和视频任务中,它也展现了组织模型之间合作的能力,通过分别并行和串行执行两个模型的方式,完了一段“宇航员在太空行走”的视频和配音作品。

此外,它还可以集成多个用户的输入资源执行简单的推理,比如在以下三张图片中,数出其中有多少匹斑马。

一句话总结:HuggingGPT可以在各种形式的复杂任务上表现出良好的性能。
项目已开源,名叫「贾维斯」
目前,HuggingGPT的论文已经发布,项目则正在建设中,代码只开源了一部分,已揽获1.4k标星。
我们注意到,它的项目名称很有意思,不叫本名HuggingGPT,而是钢铁侠里的AI管家贾维斯(JARVIS)。
有人发现它和3月份刚发布的Visual ChatGPT的思想非常像:后者HuggingGPT,主要是可调用的模型范围扩展到了更多,包括数量和类型。
不错,其实它们都有一个共同作者:微软亚研院。
具体而言,Visual ChatGPT的一作是MSRA高级研究员吴晨飞,通讯作者为MSRA首席研究员段楠。
HuggingGPT则包括两位共同一作:
Shen Yongliang,TA来自浙江大学,在MSRA实习期间完成此项工作;
Song Kaitao,MSRA研究员。
其通讯作者为浙大计算机系教授庄越挺。

最后,对于这个强大新工具的诞生,网友们很是兴奋,有人表示:
ChatGPT已成为人类创建的所有AI的总指挥官了。

也有人据此认为:
AGI可能不是一个LLM,而是由一个“中间人”LLM连接的多个相互关联的模型。

那么,我们是否已经开启“半AGI”的时代了?































